 Chapter 22 One-Way Analysis of Variance: Comparing Several Means
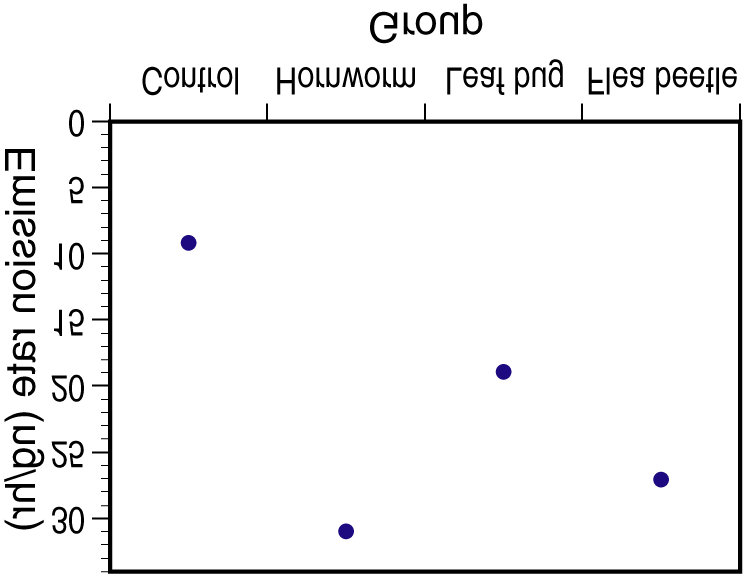
22.20. (a) We test H0: µ1 = µ2 = µ3 = µ4 = µ5 vs. Ha: not all means are the same. (b) N = 168, I = 5,
Chapter 22 One-Way Analysis of Variance: Comparing Several Means
22.20. (a) We test H0: µ1 = µ2 = µ3 = µ4 = µ5 vs. Ha: not all means are the same. (b) N = 168, I = 5, Microsoft word - bonus-malus-regelung _jäkel_.rtf
Neues von Bonus-Malus: Protonenpumpenhemmer werden aus der Bonus-Malus-Regelung herausgenommen Seit 2007 gilt für Vertragsärzte die Bonus-Malus-Regelung. Die Spitzenverbände der Krankenkassen und die Kassenärztliche Bundesvereinigung haben dafür sieben Arzneimittelgruppen festgelegt. In Berlin wurde die Vorgabe der KBV 1:1 übernom-men. Regional werden für jede dieser Arzneimittel